
The Cost of a CAE Job in the Cloud
Ten years ago, general belief was that high performance cloud computing was about five times more expensive than high performance computing (HPC) on premises, by comparing total cost in the cloud versus the cost of the on-prem compute server, often ignoring additional expenses for operations, management software, IT staff, energy, space, support, and maintenance, for the on-prem HPC server. In addition, cloud providers were quite vague about additional costs for storage, data movement and other cloud services. Over time, more detailed analyses have been published recommending how to save cost in the cloud and increase return on investment.
But one question has barely been answered: How much does one complex engineering simulation job really cost you in the cloud? Because the engineers (and their simulations) are one of the company’s core assets for product innovation, the question could also be asked: How much does innovation cost for my company? Or, how much do I have to spend to increase my next-generation product’s quality, and thus its competitiveness in the market?
The Cloud HPC Architecture
The answer can be found by zooming into an existing high-performance cloud computing architecture that is built to solve complex engineering simulation problems, in very detail. Such an architecture has been implemented, for example, for the cement and mining machinery leader FLSmidth with headquarters in Denmark, see e.g. our FLSmidth eBook. For their simulations, over the last four years, they have been using simulation software from Ansys, Siemens, and Dassault, running in the engineering cloud environment depicted in the following figure.
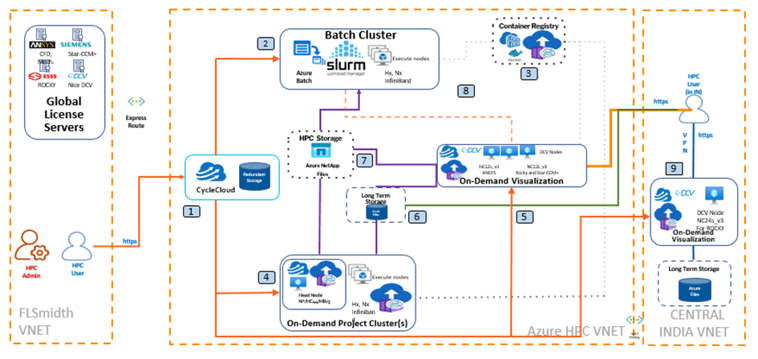
For executing an engineer’s simulation job, the following steps (which you can skip reading for now if you are just interested in the results) are performed automatically by the different cloud components, invisible for the engineer, on Microsoft’s Azure Cloud:
- The HPC user connects with CycleCloud server via Web [step 1] and creates the batch cluster with required VM types and number of VMs [2].
- The HPC user also creates an on-demand project cluster [4] for the HPC user with CycleCloud server via Web.
- The user connects with CycleCloud server via Web app [1], and by using the web interface starts/stops the on-demand visualization (GUI) node [5, 9], or on-demand project cluster(s) [4] whenever it is required.
- The user transfers the job files via Azure Storage Explorer or AzCopy from local PC to long term storage [6].
- The user connects own on-demand visualization (GUI) and transfers the job files from long term storage to HPC storage (shared) [7].
- The on-demand visualization (GUI) can be used for pre- and post-processing and batch cluster job submission [5].
- The user submits the jobs to the batch cluster [2] via SLURM command line interface (CLI) [8].
- SLURM scheduler invokes the required compute nodes [2] of the batch cluster to run the job.
- VM pulls the containerized CAE applications from the user’s container registry [3].
- The result files are stored on HPC storage [7], and the user accesses them via on-demand visualization VM [5].
- Once the job is completed, the compute nodes of the batch cluster [2] are automatically deallocated.
- If the files on HPC storages are not going to be used actively, the user can copy files from HPC storage to long term storage [7].
- The user stops on-demand visualization which deallocates node to optimize the cost and spin up again when required.
- The user also uses on-demand project cluster to use compute node interactively [4]. There is no scheduler, and user can start/deallocate compute nodes whenever required.
- The CycleCloud server [1] as well as the clusters [2,4, and 5] are deployed in the same virtual network. CycleCloud can also create on-demand visualization VMs in different regions such as Central India and West US.
Bill of Material and Total Cost for an Automotive STAR-CCM+ Simulation
Using an automotive application example, we are running a computational fluid dynamics (CFD) simulation with Siemens STAR-CCM+, for a 100-million-cell geometry, with hexa-mesh. A first benchmark run of this job on one 120-core HBv3 compute node (based on AMD EPYC Milan CPUs) in Azure resulted in 30 hours run time. Next, running the same job on 16 120-core HBv3 compute nodes (total 1920 cores) in Azure resulted in in a run time of just 1.5 hours, demonstrating an excellent scalability of this STAR-CCM+ job for this specific application, with a speed-up factor of 20, achieved by using 16 nodes and 16 times larger local memory, causing fewer memory conflicts.
Now, with all this information, it is possible to set up a Bill of Materials for all the components described above, as a basis for calculating the total cost of this job, as follows (D4SV3, D4SV4, HBv3, and NC12s_v3 are Azure compute instances).
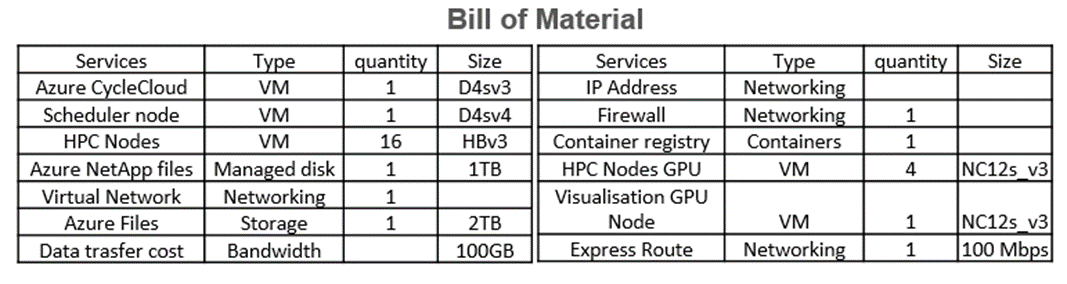
We then collected pricing information for the different components on Microsoft’s websites and with Google Search, for e.g., 100 simulation jobs per months, resulting in:
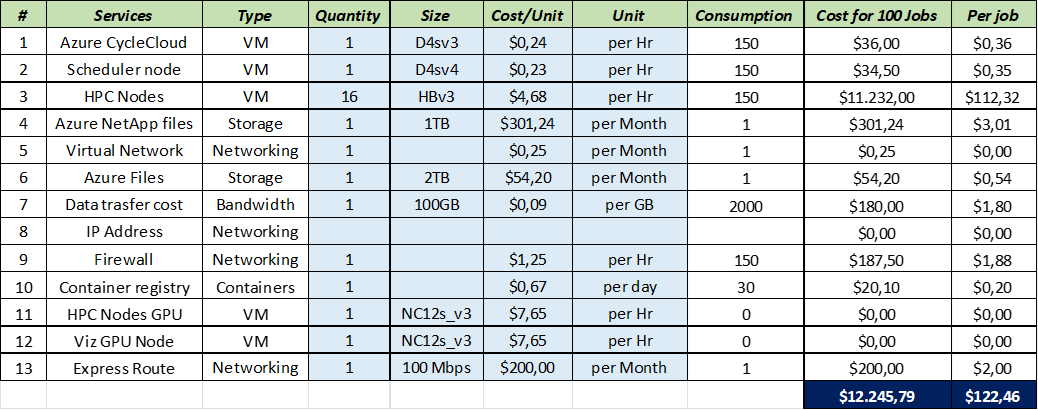
Finally, dividing $12,245.79 by the 100 jobs results in $122.45 for one STAR-CCM+ simulation job on 16 HBv3 AMD EPYC Milan-powered Azure compute instances, including all infrastructure, simulation, and data costs.
Just imagine, to verify one engineer’s innovative idea, which might dramatically improve your company’s next generation product, help avoid a product failure early in the design phase, spare expensive and time-consuming physical prototyping in the lab, discover a new revolutionary material, reduce the cost of manufacturing, or which could shorten time to market and increase your company’s competitiveness, or all of this together . . . for just $122.45! That's something that you can really take a few moments to enjoy and savor.
Discover UberCloud for you today.


