
If you ever wanted to know how useful Artificial Intelligence can be for CAE, here is one educational example.
Solving computational fluid dynamics (CFD) problems is demanding both in terms of computing power and simulation time, and requires deep expertise in CFD. In this UberCloud project #211, an Artificial Neural Network (ANN) has been applied to predicting the fluid flow given only the shape of the object that is to be simulated. The goal is to apply an ANN to solve fluid flow problems to significantly decrease time-to-solution by three (!) orders of magnitude, while preserving much of the accuracy of a traditional CFD solver. Creating a large number of simulation samples is paramount to let the neural network learn the dependencies between simulated design and the flow field around it.
Therefore, this project, conducted by Renumics in Karlsruhe and UberCloud in Sunnyvale, explores the benefits of using cloud computing resources in Advania Data Centers cloud that can be used to create a large amount of simulation samples in parallel in a fraction of the time a desktop computer would need to create them. We wanted to explore whether the overall accuracy of the neural network can be improved the more samples are being created in the UberCloud HPC/AI/OpenFOAM container based on Docker and then used during the training of the neural network.
WORKFLOW OVERVIEW
In order to create the simulation samples automatically, a comprehensive four-step Deep Learning workflow was established, as shown in Figure 1.
 Figure 1: Deep Learning workflow.
Figure 1: Deep Learning workflow.
1. Random 2D shapes are created. They have to be diverse enough to let the neural network learn the dependencies between different kinds of shapes and their respective surrounding flow fields.
2. The shapes are meshed and added to an OpenFOAM simulation template.
3. The simulation results are post-processed using the visualization tool ParaView.
4 .The simulated design and the flow fields are fed into the input queue of the neural network.
After the training, the neural network is able to infer a flow field merely from seeing the to-be-simulated design.
TRAINING RESULTS
On the engineer’s desktop computer, it took 13h 10min to create 10,000 samples, and with the UberCloud OpenFOAM container on one HPC compute node in the Advania Data Centers Cloud, it took 2h 4min, resulting in a speedup of 6.37.
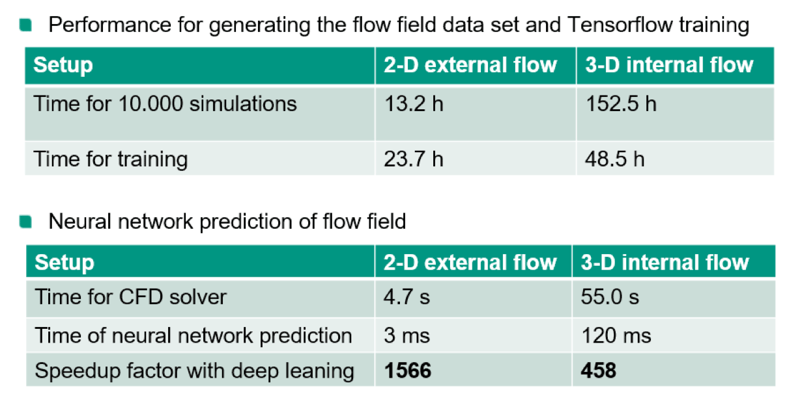 Figure 2: Performance and speedup with neural network prediction.
Figure 2: Performance and speedup with neural network prediction.
Next, a total of 70,000 samples were created. We compared the losses and accuracies of the neural network for different training set sizes. In order to determine the loss and the accuracy of the neural network, we first defined “loss of the neural network prediction.” This measure describes the difference between the prediction of the neural network and the fully simulated results. A loss of 0.0 for all samples would mean that every flow velocity field in the dataset is predicted perfectly. Similarly, the level of accuracy that the neural network achieves, had to be described. For details about the definitions of ‘loss’ and the ‘level of accuracy’ see the complete case study.
The more different samples the neural network processes during the training process the better and faster it is able to infer a flow velocity field from the shape of the simulated object suspended in the fluid. Figure 3 illustrates the difference between the ground truth flow field (left image) and the predicted flow field (right image) for one exemplary simulation sample after 300,000 training steps. Visually, no difference between the two flow fields can be made out.
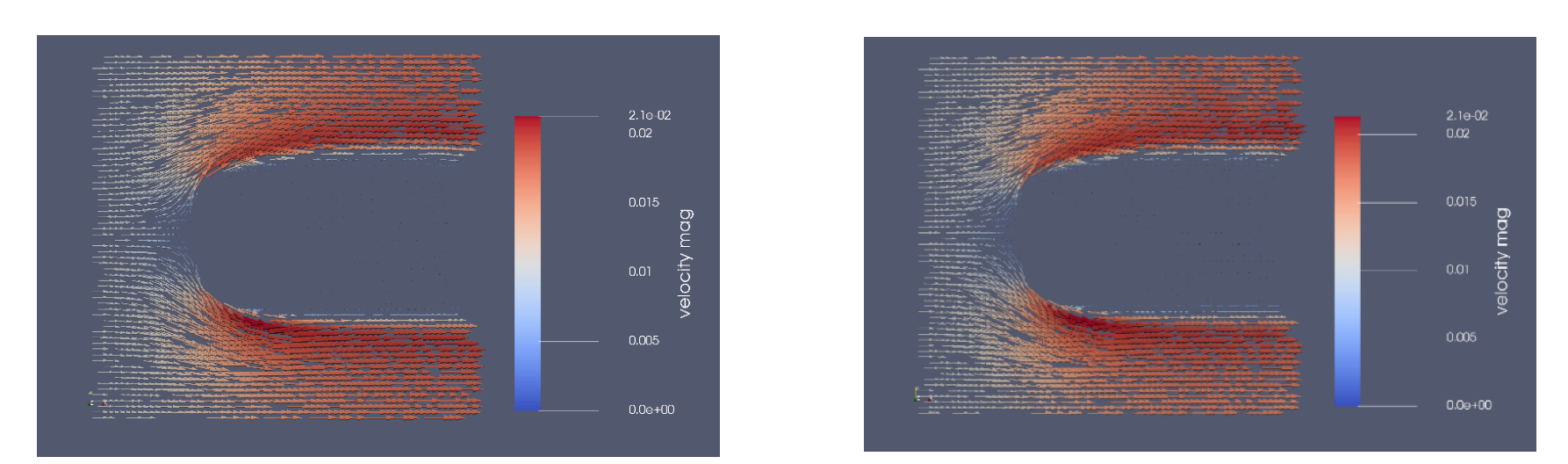 Figure 3: Simulated flow field (left image) and predicted flow field (right image).
Figure 3: Simulated flow field (left image) and predicted flow field (right image).
CONCLUSION
We were able to prove a mantra amongst machine learning engineers: The more data the better. We showed that the training of the neural network is substantially faster using a large dataset of samples compared to smaller datasets of samples. Additionally, the proposed metrics for measuring the accuracies of the neural network predictions exhibited higher values for the larger numbers of samples. The overhead of creating high volumes of additional samples can be effectively compensated by the high-performance containerized (based on Docker) computing node provided by UberCloud on the Advania Data Centers Cloud. The speed-up of 6 in the cloud compared to a state-of-the-art desktop workstation can be further reduced drastically by creating the samples on many more compute nodes in the cloud, allowing to create hundreds of thousands of samples for the neural network training process in a matter of minutes instead of days.
Acknowledgement
This project has been collaboratively performed by Jannik Zuern, PhD Student at the Autonomous Intelligent Systems Lab of the University Freiburg, Germany, supported by Renumics GmbH for Automated Computer Aided Engineering, and cloud resource provider Advania Data Centers, and sponsored by HPE and Intel. OpenFOAM and Renumics AI tools have been packaged into an UberCloud HPC software container. Thanks also to Joseph Pareti who brought this Deep Learning project to our attention.

